

図書館Linked Dataインキュベータグループ最終報告書:データセット・値語彙・メタデータ要素セット
W3Cインキュベータグループ報告 2011年10月25日
- このバージョン:
- http://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset-20111025/
- 最新のバージョン:
- http://www.w3.org/2005/Incubator/lld/XGR-lld-vocabdataset/
- 編集者
- Antoine Isaac, Europeana and Vrije Universiteit Amsterdam, Netherlands
- William Waites, University of Edinburgh (School of Informatics), UK
- Jeff Young, OCLC Online Computer Library Center, Inc., US
- Marcia Zeng, Kent State University, US (W3C Invited Expert)
翻訳もご覧ください。
Copyright c 2011 W3CR (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
概要
2010年5月に設立され、2011年8月まで継続したW3C図書館Linked Dataインキュベータグループは、
図書館コミュニティまたはそれ以外において、セマンティックウェブ、とりわけLinked
Dataの活動に関与する人々を集結し、既存の取組みの上に、将来に向けた協同作業の道筋を描くことによって、ウェブ上に存在する図書館データのグローバ
ルな相互運用性の向上に資することを目的としている。Linked Dataにおいて、データは、オブジェクトの関係性を記述する「Resource Description Framework(RDF)」、「統一資源識別子(URI、
つまり「ウェブ上の所在場所」)」といった標準を用いて表現される。当グループによる最終報告は、書誌データ・典拠データ・件名標目表・分類表といった図
書館が収集し、作成する価値ある情報資産を、本来の図書館の文脈を越えたより広範なウェブにおいて、可視性と再利用性の高いものにするために、どのように
セマンティックウェブ標準やLinked Dataの原則が適用可能であるか検証している。
データセット・値語彙・メタデータ要素セットに関する当文書は、グループの最終報告書を補完するものである。ユースケースで収集したデータをもとに、専門グループからのデータを追加し、当文書ではLinked Dataの構成要素の最新状況、特に図書館のLinked Dataの取組みに関連深い要素について概要を報告する。
当文書の状態
この章は、刊行時点における当文書の状況を記述する。その他の文書が当文書を上書きしている可能性がある。インキュベータグループ最終報告の一覧が利用可能である。http://www.w3.org/TR/のW3C技術報告インデックスも参照のこと。
W3Cインキュベータ活動
の一環として当文書がW3Cから刊行されたことは、W3Cがいかなる内容について保証することも、W3Cが当文書で言及される問題に関して何らかのリソー
スを既に割り当てている、あるいは割り当てている最中である、または今後割り当てる予定であることも意味していない。インキュベータグループへの参加およ
びW3Cにおけるインキュベータグループ報告書の刊行は、W3Cメンバーシップ特典に基づくものである。
インキュベータグループは、W3C特許方針に
規定されるとおり、利用料無料の原則のもとに成果物を制作することを目的としている。このインキュベータグループへの参加者は、後にW3C勧告に吸収され
ることになるインキュベータグループ報告書の一部に対し、W3C特許方針のライセンス要求に従って、各自のライセンスを提供することに合意している。
目次
1 はじめに:対象範囲と定義
当文書はW3C図書館Linked Dataインキュベータグループの
成果物であり、図書館分野でLinked
Dataを作成し、利用するために有用なリソース一式を識別することを目的としたものである。図書館のLinked
Data分野の概要を把握しようとする初心者だけでなく、簡易な参照や再確認をしようとする専門家も対象である。インキュベータグループがまとめた最終報告書は、
いかなる分野においてもLinked
Dataが成功するかどうかは、既に利用できるデータセットやデータモデルを利用者が識別、再利用または連係することができるかどうかに拠ることを示して
いる。図書館のLinked Dataも例外ではない。このような識別に対する取組みは、その多くが本報告書の執筆時点で既にLinked
Dataとして利用可能になっている、複雑かつ多様な図書館データリソースにとって非常に重要である。当文書がこうした取組みを実行する人々に役立つこと
を願っている。
当文書は、図書館コミュニティが自身のデータに使用する独自の観点、リソース、専門用語について、Linked
Dataコミュニティ側の理解を促す機会を提供すると同時に、図書館情報学の専門家が、伝統に即した形でLinked
Dataの考えを理解する一助となることも目的としている。過去に取り組んだ図書館専門用語の解説で、以下の種類の対象リソースを識別している。当文書の後半で明らかになるが、これらは相互排他的な関係ではない。
- データセット:
本報告書では、図書館における書籍等の事物を記述する構造化されたメタデータ集合としてのデータセットに重点を置いている。図書館界でデータセットに相当
するのは図書館レコードの集合である。図書館レコードは事象のステートメントから構成されている。このステートメントは、実体の要素(「属性」または「関
係性」)と当該要素の「値」から成る。使用する要素は、通常、MARC21やDublin Core(DC)等の標準的な要素セットから選択される。要素の値はLibrary of Congress Subject Headings等
の値語彙から採用するか、任意の文字列を用いる。「データセット」と同様の概念には「集合」や「メタデータレコードセット」が含まれる。留意すべきは、
Linked Dataのコンテクストでは、データセットは必ずしも明確に識別可能な「レコード」で構成されているわけではない点である。Linked
Dataにおいてデータセットは、メタデータとデータの厳密な区別のない、ある特定の地点からダウンロードまたは問合せが可能な一貫したトリプルにすぎな
い。この考えは、図書館コミュニティが定義域や値域を設定したResource Description Framework (RDF)語彙やベストプラクティスに
準拠したドキュメントを作成または再利用するような場合に、自身のデータに対する見方に影響を与えることになる。さらに「伝統的な」記述メタデータを他の
種類のデータとともに使用している応用事例が出てきているように、図書館データは恐らく全く異なる形に変わっていくことになるだろう。
例:
- ある特定の本のデータセットから成るレコードはDublin Coreの主題要素とLCSHの主題の値が付与され得る。
- 同一データセットには、本とリンクしている第一実体としての著者のレコードを含むことがある。これは、Friend of a Friend
(FOAF)の"name"のような要素で記述されている。
- データセットは、個別の実体として、それ自体の情報も含む点で自己記述的といえるかもしれない。例えば、Dublin Coreから修正日や維持管理者の要素を使用する場合である。
- 値語彙:
値語彙は、トピック、芸術様式、著者等、メタデータレコードにおいて要素の値として使われるリソースを定義する。一般的に、値語彙では、本のような書誌リ
ソースは定義せず、人、言語、国等、書誌リソースに関連する概念を定義する。これらは「構成単位」であり、メタデータレコードが付与されうる。ある特定の
メタデータ要素の値を選択するために特別な語彙を必須とする図書館が多い。値語彙は、ある要素で使用できる値を統制したリストを表している。例えば、シ
ソーラス、コード一覧、用語一覧、分類体系、件名標目リスト、分類、典拠ファイル、デジタル地名辞書、概念スキーマ、またはその他種類の知識組織化体系等
が挙げられる。データをリンクする際に役立つよう、値語彙はハイパーテキスト転送プロトコル(Hypertext Transfer Protocol:HTTP)や統一資源識別子(Uniform Resource Identifier:URI)を各値に付与するべきである。その際、これらの識別子はリテラル値の代わりに、またはリテラル値と併せてメタデータ中に使用する。
例:
- メタデータ要素セットまたは要素セット:
メタデータ要素セットでは対象となる実体を記述するためのクラスと属性を定義している。Linked Data の用語では、このような要素セットは、RDFスキーマやOWLウェブオントロジー言語を用いて一般的に具体化されており、これらを包括する用語として「RDF語彙」がよく使用される。通常、メタデータ要素セットは書誌的な実体を記述せず、こうした実体を記述するために他で使われる要素を提供する。
例:
本報告書では、初心者がメタデータ要素セット、値語彙、データセットの例を発見、理解、検索するための手引きとなることを目的としている。また、本報告書は、主にIncubator Groupが収集した事例に基づいている。ここでは図書館に関連するLinked Dataの「クラウド」に関する多様なリソースの完全なリストを提供することを目指してはいない。この報告書がSindiceやFalcons等のSemantic Web 対応サーチエンジンのようなより完全なリスト作成ツール、Linked Open Vocabulariesのような他の調査、Open Metadata Registry・Schemapedia・Data Hubのようなレジストリを利用する際の参考となることを期待している。筆者自身がData Hubレジストリを利用したのと同様に、読者にもこれらを使用することを推奨したい。
2 Data Hub における図書館のLinked Data
Data Hubはデータ用レジストリである。あらゆるタイプのデータ「集合」に関する情報を共有し、共同で編集できるサイトである。Data Hubレジストリ自体はLinked Dataサービスではないが、登録されている情報のLinked Dataバージョンがある。 Data Hubに登録されているデータの多くがLinked Data形式である。
Data Hub は、コミュニティが管理するグループごとにデータ集合を組織化している。より広範なLODクラウドの構成要素に関する情報だけでなく、図書館のLinked Dataに
関連するサブセットの情報も維持管理している。これには上述の図書館データセットと値語彙の両方が含まれる。追加される集合を記述するために、グループの
管理者たちはData Hubにタグ付け機能を使用するのを慣例としている。下記の一覧には、データ量やリソース例、アクセス方法(例:SPARQL
ProtocolやRDF Query Language (SPARQL)エンドポイント)、そして最も重要なものとして、その他データ集合へのリンクに関する情報も含まれている。
参照:
Data Hubにデータ集合を新規追加することで可視性が向上する。Data
Hubは頻繁に参照されるデータ集合の一覧となっている。LODクラウドと図書館のLinked
Dataグループの規則に準拠することで、他のデータ集合との関係性は確実に記録できるようになり、増大するLinked
Dataの集合体の一部として認識されるようになる。ここに掲載されるデータセットは、Linked
Data研究の一部として作成される図表として示されることになる。データに関する情報を一貫して文書化することは、その性質や組合せ方法をより深く理解
するためのツールを開発できることを意味する。このプロセスは興味深いと同時に重要である。というのも、このように理解することで特定のデータ集合がある
取組みに適しているかどうかを判断しやすくなり、データが利用しやすくなるからである。
このプロセスの結果の例を説明するために、下記の図を見てみよう。
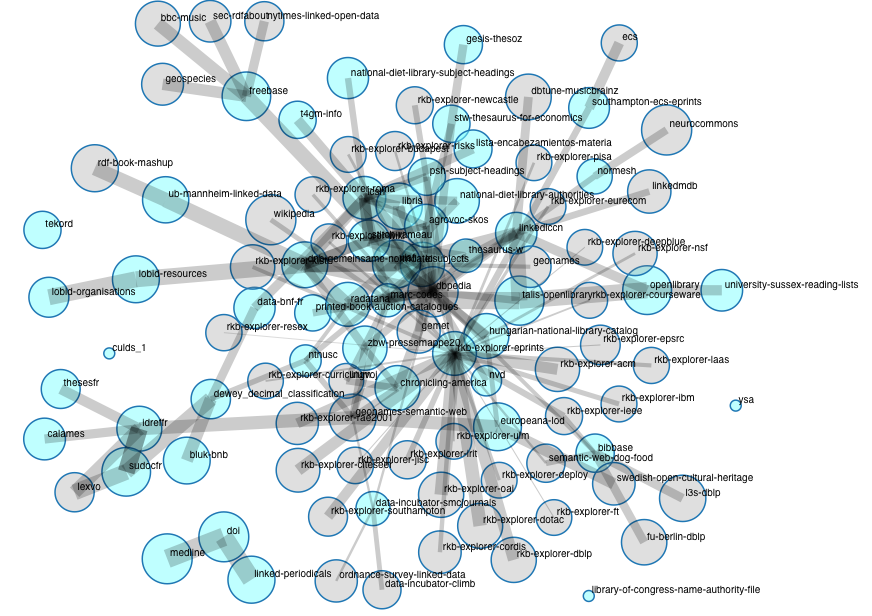
スナップショットの更新版はhttp://semantic.ckan.net/group/?group=http://ckan.net/group/lldを参照のこと。
明るい色の円はData Hubにおける図書館のLinked
Dataグループに属するデータ集合を示している。灰色の円はこのグループには属さないが関連のあるデータ集合を示している(一般的にData
Hubにおける図書館のLinked
Dataグループに属している)。円の大きさと線の太さはデータ量と外部へのリンク数(対数換算)にそれぞれ連動している。
この図はアルゴリズムに基づき自動的に生成され、本報告書公開時点でのData Hubにおける図書館のLinked Data
グループの状態を表している。この報告書を作成し始めてから既に大幅に改訂されているため、この図は近い将来変わる可能性がある。例えば、この報告書作成
当時、Library of Congress Name Authority Fileは公開されたばかりで他と繋がりを持っていないように見えるが、数ヵ月後には変わる可能性が高い。
この図は、Linked Open
Dataの最近の急増を反映し、進化し続ける複雑なウェブのリンクを表現することの難しさを示している。しかし、図書館のLinked
Dataには密接に繋がったデータ集合群があり、図書館由来ではないデータセットを介して実際に繋がっていることが一見してわかる。特にDBpediaやGeoNames経由のものが顕著である。また、明らかに、データのハブから外側の他のデータへと繋がる方法が一般的である。有用なのはデータのハブだけではない。
3 公開されているデータセット
この項では、本報告書公開時点においてData Hubの図書館のLinked Dataグループで利用可能となっている全データセットを挙げている。ほとんどは書誌データに関するデータセットである。詳細は、個々のデータ集合へのリンクを参照すること。
- BibBase
- BibBase.orgはインターネット上での科学出版物の流通を促進している。
- British National Bibliography (BNB)
- Linked Data形式で公開された英国全国書誌(BNB)
であり、VIAF、LCSH、Lexvo、GeoNames、MARC国名コード・言語コード、Dewey.info、RDF Book Mashup等の外部情報源とリンクしている。
- Calames
- Calamesは、ABESが維持管理する、フランスの文書および書写資料の学術機関総合目録である。
- Chronicling America
- Chronicling Americaでは歴史上重要な新聞に関する情報とデジタル化した新聞に関する情報を提供している。14万タイトル、320万ページが収録されている。
- Cambridge University Library dataset #1
-
このデータはCOMETプロジェクトの最初の重要な成果物である。これはJISCの助成によるケンブリッジ大学図書館とCARET間の連携プロジェクトである。
- data.bnf.fr - Bibliotheque nationale de France
-
data.bnf.frでは、BnFの様々なデータベースからデータを収集し、作品や著者に関するウェブページを作成し、抽出データとともにRDF形式で表示する。
- Scottish Mountaineering Council Journals Issues 1-36
- 「Scottish Mountaineering Club Journal Issues 1 to 36,
1890-1901」のデジタルアーカイブであり、Scottish Mountaineering
Trustから資金提供を受け、ストラスクライド大学のAlan Dawson氏が作成したものである。
- CrossRef DOI Resolver
-
デジタルオブジェクト識別子(DOI)は、約3,000件の出版社が主に学術出版物のドキュメントを識別するために採用している永続的な識別方法である。
- Europeana Linked Open Data
- data.europeana.euの試作版は、Europeanaがメタデータをウェブ上でLinked Open Dataとして利用できるようにする取組みの一つである。現在、350万件の資料に関するメタデータが利用できる。
- Freebase
-
Freebaseは世界の情報に関するオープンなデータベースである。コミュニティによってコミュニティのために構築されている。誰でも自由に検索、編集、アプリケーション開発、各自ウェブサイトへの統合が可能である。
- Hungarian National Library (NSZL) catalog
- OPACとデジタルライブラリ、それに対応する典拠データがLinked Open Data形式で提供されている。
- Linked Periodicals Database
- Linked Periodicals Databaseは、CrossRefやHighwire Press、国立医学図書館が提供する論文メタデータを集めるData Incubatorのデータセットである。
- lobid. Index of libraries and related organisations
-
lobid-organizationsは、国際標準として策定された「図書館および関連組織のための国際標準識別子(ISIL)」に基づく図書館機関のためのURIを提供している。
- lobid.
Bibliographic Resources
-
lobid-resourcesは、書誌的リソース(図書、論文記事、PDF等)に関するメタデータへのアクセス提供サービスである。現在のレコード数は700万件以上である。
- medline
- Medline のRDF版。雑誌の識別子http://crossref.org/と論文の識別子http://dx.doi.org/にリンクされている約1,900万件の論文記事に関する情報を提供している。
- NTNU special collections
-
ノルウェー科学技術大学(NTNU)が特別コレクションとして所蔵している歴史的に重要な書写資料をデジタル化したコレクション。
- The Open Library
-
これまでに出版された各書籍ごとに一つのウェブページを用意している。現在、2,000万件以上のレコードが多様な大規模目録から収集されるほか、個々人によって新規作成・更新されている。
- English Language Books listed in Printed Book Auction Catalogs from 17th Century Holland
- オランダで印刷された学者や聖職者のコレクションのオークションカタログの英語版に掲載されている図書。
- ePrints3 Institutional Archive Collection (RKBExplorer)
- 多数のePrints3アーカイブのLinked Data版。
- ECS Southampton EPrints
- EPrintsサーバで提供されている生データ。RKB Explorerの提供サービスとは異なる。
- Sudoc bibliographic data
- Sudocは、ABESが維持管理するフランスの学術総合目録である。1,000万件以上の書誌レコードが収録されている。
- Open Library data mirror in the Talis Platform
- Open libraryのJSON形式のダンプデータを使ってモデル化したもの。SPARQL
endpointとOpenSearchインターフェイス(RSS 1.0出力)を提供している。
- theses.fr
- theses.frは、ABESが維持管理するフランスの論文検索エンジンである。
- Linked Data Service der Universitatsbibliothek Mannheim
- 多くの書誌的リソースをRDF形式で公開したもの。Sudwestdeutscher Bibliotheksverbund、Hessisches Bibliotheksinformationssystemの書誌データ等を含む。
- University of Sussex Reading Lists
- 大学の図書目録検索エンジンで利用できるリソースのLinked Data版。
- 20th Century Press Archives
- 主に個人、会社、その他法人、製品や広範な経済関連テーマについての新聞の切り抜き等の3,000万件以上のドキュメントを提供している。
4 値語彙
4.1 公開されている値語彙
本項では、Linked Dataとして利用できる、またはインキュベータグループのユースケースで関連性があると言及されている値語彙について説明する。
いずれも語彙の簡単な紹介とリンクを記載する。インキュベータグループが収集した値語彙への参照事例も各項目下に挙げている。
4.1.1 分類体系
Dewey Summariesは、デューイ十進分類法(DDC)第22版の上位クラスを収録した適切なデータセットである。DDCの上位3階層までを11ヶ国語で提供している。また、要約版14版(番号とキャプション)についても3ヶ国語で提供している。
国際十進分類法(UDC)はあらゆる領域の知識のための多言語分類体系である。UDC
Summaryでは、UDCの体系から抽出した約2,000種類のクラスが表現されている。[1]
4.1.2 件名標目/件名典拠ファイル
LCSHは、紙媒体とLinked Data形式で公開されている広範囲にわたる件名標目一覧である。件名典拠標目は、Library of Congress Authorities and Vocabulariesサービス経由でアクセスできる。
RAMEAUはフランス国立図書館(BnF)が使用する件名標目である。米国議会図書館件名標目表(LCSH)にその起源を持ち、ケベック大学により件名標目リポジトリが最初に開発された。RAMEAUはTELplusプロジェクトによりLinked Dataとして公開されている。
ドイツ国立図書館(DNB)が多様な図書館ネットワークと連携して管理する統制語彙システム。SWDに収録されるキーワードは
「件名目録規則」(RSWK)で定義されている。[2]
国立国会図書館件名標目表(NDLSH)は、国立国会図書館の目録で適用する件名標目の一覧であり、主に普通件名と一部の固有名件名が収録されている。[3]
4.1.3 名称典拠データ
VIAFは世界中の国立図書館の共同プロジェクトであり、参加機関の名称典拠ファイルを一つの名称典拠サービスへ仮想的に統合する。この報告書の公開時点では、VIAFに参加している18機関の個人名・団体名・会議名の典拠ファイル21種類が収録されている。[4]
ULANは、225,000件以上の人名に加え、芸術家・建築家の経歴や書誌情報から成る構造化された語彙である。人名には、別名、筆名、別言語名等も含まれる。
ULANは、Linked Dataとしてはまだ公開されていないが、ゲッティ研究所の成果物としてVIAFに収録されている。
LC/NAFでは個人、団体、出来事、場所およびタイトルに関する名称典拠データを提供している。様々な目録方針に基づき、数十年間かけて作成された800万件以上のレコードである。LCの名称典拠は、公式には名称典拠ファイル共同作成プログラム
(NACO)の典拠ファイルとよばれており、参加機関が共通の標準やガイドラインに準拠して共同で作成した成果である。
GeoNamesは1,000万件以上の地名と750万件の固有名から成る。そのうち280万件が居住地名、550万件が別名である。[5]
4.1.4 シソーラス
このシソーラスは経済に関する語彙を提供する。また、法律や社会学、政治学や地名として使用される専門用語にも対応している。[6]
AGROVOCは、国際連合食糧農業機関(FAO)による多言語対応の構造化された統制語彙である。農業、林業、漁業、
食品、その他環境等の関連分野のあらゆる専門用語を対象として作られている。[7]
Eurovocは、EUの取組みの中でも特に欧州議会の活動を対象とした総合的な多言語対応シソーラスである。本報告書公開時点で24カ国語の語彙が収録されている。
[8]
米国議会図書館のThesaurus for Graphic
Materialsには、写真に示されているトピックをインデックス化した7,000件以上の主題語が含まれている。また、写真、印刷物、設計図、エフェ
メラ等の種別を索引付けした650件のジャンル/形式用語も収録されている。[9]
4.1.5 その他統制語彙
Dublin Core Metadata Initiative (DCMI)により策定された一般的な分野共通の用語リスト。リソースのジャンルを識別するための要素の値として使用される。
MARC (MAchine-Readable Cataloging)
Relatorsでは、著者名と書誌的リソース間の関係性を記述するためのプロパティの値リストを提供している。
PRONOMは、ファイルフォーマットやソフトウェア製品、その他技術的要素に関する技術情報のオンラインレジストリである。これらの情報は、文化的、歴史的、商業的に価値のある電子記録やデジタルオブジェクトの長期的なアクセスに必要である。
[10]
Creative Commonsでは、著作権法が規定する従来の「all rights reserved」(無断複写・転載禁止)の枠組みの中で調和をとるための著作権ライセンスとツールから成る基盤を提供している。[11]
Preservation vocabularies from LoC [米国議会図書館による保存のための語彙]
主に2種類の語彙集が提供されている。Preservation Eventsは、保存リポジトリ内のデジタルオブジェクトに対する活動など、保存事象に関する概念体系である。Preservation Level Roleは、どのような場合に保存に関するオプションを適用できるかを特定する値など、保存レベルごとの役割に関する概念体系である。
4.1.6 その他情報源
WordNetは英語の語彙データベースである。名詞、動詞、形容詞および副詞を「synsets」と呼ばれる同義語のグループに分類している。synsetごとに異なる概念を表現する。概念上の意味的または語彙的な関係によりsynsetは相互にリンクしている。[12]
Wordnetはアムステルダム自由大学によってLinked Data形式で公開されている。
Freebaseはオープンな、クリエイティブコモンズのライセンス下で提供される構造化データの集合であり、Freebase API経由でデータの操作やアクセスができるプラットフォームである。Freebaseは、Wikipedia、MusicBrainz等の自由利用可能な多様な情報源からデータを取り込んでいる。[13]
Freebaseは基本的にデータセットであるが、多くの参照リソースを持つため特定のケースで部分的に値語彙としても使用できる点に留意が必要である。
DBpediaではWikipediaから構造化された情報を抽出する。DBpediaのデータセットは300万件以上の物事の名称や概要を示している。そのうち半数はオントロジーを用いて分類されている。また、データセットには、画像や外部ウェブページへのリンクや他のRDFデータセットへの外部リンクも数100万件収録されている。[14]
Freebaseと同様、DBpediaも総合的なデータセットと見なすことができるが、場所、人物、「分類」といった記述対象の実体の中には、場合によっては、参照のための値語彙として用いられるものもある。
4.2 進行中または公式には進行していない関連事例
当該シソーラスはAquatic Sciences and Fisheries Abstracts
(ASFA)の主題索引として使われている。海洋資源・汽水・淡水・環境の科学・技術・経営・保全に関する世界中の文献を対象とする抄録・索引サービスで
ある。社会経済または法的な観点も含まれている。
Fisheries Reference Metadataシステムでは、漁業の捕獲、生産に関する時系列データや種のファクトシートのような漁業観測データを記録するためのFAOの全分類体系が収録されている。
Agricultural Thesaurus and
Glossaryは、米国農務省の米国農業図書館(NAL)が提供する英語またはスペイン語の農業用語のオンライン語彙ツールである。このシソーラスでは
農業に関する主題の範囲が幅広く定義されており、生物学、物理学、社会科学等の専門用語も収録されている。シソーラスに収録されている用語の定義は
Glossary of Agricultural Termsとして公開されている。[15]
美術、建築、装飾美術、記録資料、物質文化に関する多言語対応の統制語彙集。索引、目録、検索を目的とした検索ツールである。
国立医学図書館(NLM)が提供する生物医学や健康関連情報や文書を対象とした総合的な統制語彙集。スペイン語およびフランス語版のMeSHがセマンティックウェブの用語集としてBioPortalで利用できる。ノルウェー語版MeSHがノルウェー科学技術大学によりLinked Data形式で公開されている。また、SKOS版がOCLC Terminology Servicesを通じて利用できる。
絵画、スケッチ、写真等の多様な媒体に表現された画像の主題を記録および分類するための分類体系。
1,300万件以上の名称を収録した世界全体に対応した構造化された語彙集。土地固有の用語や歴史的な用語、座標、地形タイプ、解説事項等が含まれ、美術・建築研究に重要な場所に重点が置かれている。
4.3 図書館のLinked Dataに関連するその他値語彙
New York Timesでは、Times
Topicsのページを動作させるのに、約3万件のタグを使用している。「人」「組織」「場所」「識別子」にカテゴリ化されたタグがLinked
Data形式で公開されており、FreebaseやDBpedia、GeoNamesにマッピングされている。
MARC国名リストでは、国家、アメリカ合衆国の州、カナダ・オーストラリアの州、イギリスの各地域、国際的に独立国として認識している国々を識別する。対応するISO 3166コードへの参照情報も含まれている。
MARC 言語リストでは、言語とそのグループの識別子としてアルファベット小文字3文字を付与している。ISOの639-1・639-2・639-5の対応するコードとの相互参照が含まれている。
MARC 地名リストは国、首都、地域、地理的特性、大気圏外エリア、天体等を識別する。リストには550件以上のコードが収録されている。[16]
5 メタデータ要素セット
この章では、2010~2011年に図書館Linked Dataグループが収集した事例で言及されているメタデータ要素セットを挙げる。図書館分野のデータを生成または変換するために利用可能なセマンティックウェブ技術を再利用したい実践者に最適のRDF語彙も含まれている。
RDF語彙はRDFスキーマ(RDFS)やOWL ウェブオントロジー言語といったモデリング言語による概念を使って表現される。管理者が提供する文書に加え、オントロジーは、ProtegeやManchester ontology browser、OWL Sight、Live OWL Documentation Environment (LODE)等の一般的なオントロジー生成・視覚化ツールを用いて見ることもできる。(LODE上でのDescription of a Project (DOAP)オントロジー表示例を参照。)
各要素セットに対して、人間が読めるウェブサイトへのリンクや、XML名前空間宣言構文を用いて、対応するRDF名
前空間や共通の接頭辞を示している。また、要素セットの主な対象や使用範囲に重点を置いた簡潔な記述を提供または再利用する。この章は、要素セットを特徴
づける重要な設計上の決定に力点を置いている。これには要素セット同士を関連させるかどうかの指示や従来の図書館の利用方法に関するものも含まれている。
最終的に、インキュベータグループが収集した事例は関連する使用例としても挙げている。
説明するため、Paul Walkが作成したサイトを用いて、この章で示される要素セットのタグクラウド表示も載せている。

このタグクラウドはメタデータ要素セットの利用という固有の文脈を反映したスナップショットである点に留意する必要がある。特に、各タグの大きさは、図書館Linked Dataインキュベータグループが収集したその要素を使用している個々の事例数に比例している。インキュベータグループの事例に基づく分析だけでなく、図書館Linked Dataコミュニティのメンバーは、Data Hub Library Linked Dataグループのように正確かつ最新のデータセットと値語彙のリストを維持できるよう検討するべきである。これにより、要素セットの利用方法について評価できるようになる。詳細な特定分野ごとのLinked Open Data Cloudの利用統計を使用することで、コミュニティは幅広く使われている要素セットや特殊な要素セットに関するより明確なアイディアを生み出すことができる。
メタデータ要素セット間のリンクを可視化することは、複数の語彙データを再利用し、幅広いコミュニティによってデータがより使いやすくなることを望む実践者にとって大きな価値を持つ。Upper Mapping and Binding Exchange Layer (UMBEL)
constellationは普及しているLinked Data語彙間の関連を最初に示したものである。Linked Open Vocabulary の取組みは、こうした情報の収集と自動化を可能にしている。Dublin Coreのような大規模なメタデータ要素セットに対して、Linked Open Vocabularyは、機械可読形式での定義(オントロジー)に基づき、他の要素セットとの詳細な関連性を示している。
5.1 RDF語彙として公開されているメタデータ要素セット
この項では、本報告書作成時点で利用可能な、OWLやRDFSと
いった関連するオントロジーを挙げる。利用者が理解しやすいよう、図書館、文書館、博物館、情報コミュニティに由来するメタデータ要素セットをはじめに紹
介する。その後、他のコミュニティ由来の関連する要素セットを示す。多くの語彙が既にコミュニティを横断したプロジェクトにより作成されているため、この
分類は恣意的なものである。しかし、これにより、様々な由来を持つ要素セットを容易に共有、再利用、拡張することが標準的に可能となるLinked
Dataの手法に大きな可能性が秘められていることが示される。
図書館、美術館、博物館、その他情報コミュニティ由来
情報リソースを記述するための基本15要素であるDublin Core メタデータ要素セットのオリジナルのプロパティは、名前空間http://purl.org/dc/elements/1.1/を使って識別されている。これらのプロパティは、2004年にRDFSが最終化される以前の2000年にRDFプロパティとして定義されており、値域(rdfs:range)に制約が設けられていない。そのため、文字列の値にも、本格的なRDFリソースにも、これらのプロパティを使用することができる。
より数の多い語彙セットであるDCMIメタデータ語彙(http://purl.org
/dc/terms/)における第二の名前空間には、値域に「制約がない」/elements/1.1/プロパティと同様の15要素が含まれるが、値域に
よる制約のほか、数十のプロパティが追加されている。「制約がある」/terms/プロパティと「制約がない」/element/1.1/プロパティは、
下位プロパティ(rdfs:subPropertyOf)の関係で結ばれることにより、相互運用性が担保されている。
- xmlns:dc="http://purl.org/dc/elements/1.1/"
- xmlns:dcterms="http://purl.org/dc/terms/"
- 使用例:強化された出版物, Publishing 20th Century Press Archives, Data BNF, VIAF,
異なるシソーラスを用いたリポジトリにおける検索・閲覧, Pode, Archipel, SEO, LOCAH, デジタルテキストリポジトリ,
Europeana, 過去の図書館データの移行,
図書館の所在地データ, NLL Digitized Map Archive,
Open Libraryのコースに関連する資料収集
OAI-OREモデルではウェブリソースの集合体を記述するための要素を定義している。これは、論文記事やとそのデジタル形式、付属資料等の複合したデジ
タルオブジェクトを形成する。また、リソースが異なる集合体に含まれている場合に、この集合体に関するメタデータの来歴を示し、記述するための「リソース
マップ」や、特定の集合体の観点から所与のリソースを記述するための「プロキシ」の仕組みも提示している。
SKOSはシソーラス、分類体系、件名標目表、タクソノミー、フォークソノミー、その他同種の統制語彙のような概念体系の内容と基本構造を表現するモデルを提供している。[17] SKOSではあらゆる種類のリソースにも再利用できるように、いくつかのプロパティ(特にラベルや注記プロパティ)にrdfs:domainsを意図的に指定しないようにしている。
- xmlns:skos="http://www.w3.org/2004/02/skos/core#"
- 使用例:Publishing 20th Century Press Archives, Data BNF, LOCAH,
異なるシソーラスを用いたリポジトリにおける検索・閲覧, 構成要素となる語彙, Pode, 主題検索, Europeana, VIAF, AGROVOC Thesaurus,
AGRIS, 語彙結合 (SKOS mapping),
過去の図書館データの移行,
NLL Digitized Map Archive,
Open Libraryのコースに関連する資料収集
SKOS-XLは概念に対応する名称実体の記述をサポートするSKOS拡張版である。skos:Concepts属性を具体化し、完全なRDFリソースとして扱う。これにより、さらに情報を付加したり、例えば「~の翻訳である(isTranslationOf)」属性を使ってリソース間を関連付けたりすることができる。
MARC Relators 語彙集は名称と書誌的リソースの関連性を記述するためのプロパティのリストを提供する。
- xmlns="http://id.loc.gov/vocabulary/relators"
- 使用例:構成要素となる語彙
CIDOCのオブジェクト指向の概念参照モデル(CRM)は、文化部門のオブジェクトを相互運用可能な形で記述するために国際博物館会議(ICOM)が開発したものである。このモデルは、オブジェクト、人、場所、概念を一つに関連付けるために出来事に関する実体を多用している。
その他、OWL-Description Logic(OWL-DL)版(OWL1および2)がhttp://erlangen-crm.org(名前空間:http://erlangen-crm.org/current/)とhttp://bloody-byte.net/rdf/cidoc-crm/
(名前空間:http://purl.org/NET/cidoc-crm/core#)で利用できる。
Dublin Core コレクション記述語彙
DCMIコレクション記述コミュニティのタスクグループがDublin Coreコレクションのアプリケーションプロファイルと語彙集を作成した。これは、Research Support Libraries Programme (RSLP) コレクション記述スキーマに基づいている。
- Dublin Core コレクション記述語彙
- xmlns:cld="http://purl.org/cld/terms/"
-
コレクションレベルの記述用アプリケーションプロファイルで利用するために作成されたプロパティ、クラス、語彙符号化スキーム、構文符号化スキームを記述する。
- Dublin Core コレクション記述タイプ語彙
- xmlns:cdtype="http://purl.org/cld/cdtype/"
- コレクションを記述する際のプロパティdc:typeの値として使用できるクラスを提供する。
- Dublin Core コレクション追加方法記述語彙
- xmlns:accmeth="http://purl.org/cld/accmeth/"
-
コレクションを記述する際のプロパティdcterms:accrualMethod(訳注:原文はdcterms:accrualPolicy。誤記と考えられるため、日本語訳では修正。)の値として使用できる語彙を提供する。
- Dublin Core コレクション追加頻度記述語彙
- xmlns:freq="http://purl.org/cld/freq/"
- コレクションを記述する際のプロパティdcterms:accrualPeriodicity の値として使用できる語彙を提供する。
- Dublin Core コレクション追加方針記述語彙
- xmlns:accpol="http://purl.org/cld/accpol/"
- コレクションを記述する際のプロパティdcterms:accrualPolicyの値として使用できる語彙を提供する。
書誌レコードの機能要件 (FRBR)
と関連オントロジー
FRBRは、国際図書館連盟(IFLA)が「書誌レコードに記録されているデータと目録利用者のニーズを関連付ける枠組みを提供するために開発した」(FRBR最終報告書
2.1章)概念的な参照モデルである。詳細はこちらを参照のこと。
IFLAの「FRBR」ファミリーは、書誌レコードおよび典拠レコードに記録される書誌的事項を対象とする、3つの概念モデルから構成されている。各モデルで定義される実体、属性、関連の要素は、Open Metadata Registryに収録されている。
FRBR最終報告書では、他のオントロジーで実装されている実体-関連モデルについて説明している。
ISBD統合版のクラスとプロパティを仮登録したもの。ISBD (詳細はこちらを参照のこと。)はあらゆる目録における書誌的リソースの記述に有用であり、適用可能である。
MADS/RDFは、名称(個人名、団体名、地名等)、シソーラス、分類法、件名標目、その他統制語彙リストの統制語彙を使用するように設計されている。MADS/RDFオントロジーはSKOSにマッピングされている。
- xmlns:mads="http://www.loc.gov/mads/rdf/v1#"
- 使用例:構成要素となる語彙
ドイツ国立図書館は、Linked Dataサービス向けに、典拠リソースを詳細に記述するための名前空間を定義している(Gemeinsame NormDatei:GND)。この名前空間で規定されるクラスとプロパティのセットは、特にSKOSとRDA語彙による表現の可能性を高めている。
その他コミュニティ由来
FOAFは人物や人物間の関係性、ウェブリソースとの関係性を記述するために広く普及しているオントロジーである。
- xmlns:foaf="http://xmlns.com/foaf/0.1/"
- 使用例:強化された出版物, Data BNF, Pode, SEO, デジタルテキストリポジトリ,
FAO Authority Description Concept Scheme, VIAF, LOCAH, 図書館の所在地データ, Open Library Data, 典拠データの強化, International Registry for Authors,
AGRIS,
Open Libraryのコースに関連する資料収集, Talis Prism 3
VoIDはリンク付けされたデータセットを記述するためのRDFに準拠したスキーマである。VoIDを用いることで、リンク付けされたデータセットを効率的かつ効果的に発見し、使用することができる。VoIDデータセットはデータの集合であり、一人の提供者によって公開され、維持管理されている。例えば、参照解決可能なHTTP
URI やSPARQLエンドポイントを通じてRDF形式で利用できる。
BIBOは引用または文書分類用のオントロジーとして使用でき、全ての書誌的事項をRDFで記述するための方法としても使うことができる。
- xmlns:bibo="http://purl.org/ontology/bibo/"
- 使用例:書誌ネットワーク, LOCAH, コミュニティにおける情報サービス,
地域的カタログ, Pode, 過去の図書館データの移行,
Talis Prism 3, FAO Authority Description Concept Scheme,
AGRISInternational Registry for Authors, NDNP (National Digital Newspaper Program),
Open Libraryのコースに関連する資料収集, デジタルテキストリポジトリ
Upper Mapping and Binding Exchange Layer (UMBEL)
参照概念データセットはOpenCycオントロジー由来のものである。これは数千の論理的に構造化されリンク付けされた概念を収録し、知識分野への定位ノードとして幅広く適用できる。UMBEL語彙では概念的な知識を記述するためのクラスとプロパティを提供している。また、分類オントロジーを構築するための基盤として機能することも目的としている。[18]
UMBEL vocabularyは可能な限り、外部の語彙を再利用している。
- xmlns:umbel="http://umbel.org/umbel#"
- 使用例:VIAF
vCardオントロジーによってvCard
(RFC2426)で定義されている名刺の属性を表現することができる。
- xmlns:vcard="http://www.w3.org/2006/vcard/ns#"
- 使用例:図書館の所在地データ
Lexvoという名称は古代ギリシャ語のλεξικ?ν (用語集)とラテン語vocabularium (語彙)が由来である。[19]
言語、単語、特性、その他言語に関連するオブジェクトにグローバルなURIを定義するための語彙を提供している。
- xmlns:lvont="http://lexvo.org/ontology#"
- 使用例:Pode
EXIF用のRDFスキーマである。EXIFは主に技術メタデータをサポートする画像のデータ標準であり、通常画像ファイル(例:JPEGファイル)に埋め込まれている。EXIF仕様の各要素が対応するプロパティに直接マッピングされている。オリジナルのEXIF仕様で提供されているメタデータ要素のグループ(例 ピクセル要素、地理的な位置情報)を保存するため、EXIF OWL ontologyのような他の取組みも報告されている。[20]
Open Provenance Model は来歴に関する情報を表現し共有するための総合モデルである。基本的な来歴に関するデータを表示できる軽量なモデルであるOpen Provenance Model Vocabularyと、推論に対応した表現力の高いOpen Provenance Model OWL
Specificationで構成されている。
- xmlns:opmv="http://purl.org/net/opmv/ns#"
- xmlns:opmo="http://openprovenance.org/model/opmo#"
- 使用例:科学データセットの引用情報
「Music Ontology Specificationは、セマンティックウェブ上で、音楽(例:アーティスト、アルバム名、トラック名)を記述するための主要な概念とプロパティをセマンティックウェブ上で提供している。」FRBRモデルを音楽分野に適用している。
CC RELでは著作権ライセンスをRDFで記述することができる。
- xmlns:cc="http://creativecommons.org/ns#"
- 使用例:SEO
CiTOはSPARオントロジーの一つであり、研究論文における参照引用情報を記述するための最小限のオントロジーである。
Description of a Project (DOAP)は、ソフトウェアプロジェクト、特にオープンソースプロジェクトを記述するための語彙である。
この小規模なオントロジーは、WGS84標準に準拠し、空間的なオブジェクトに対し地理的な位置情報(緯度、経度、高度)を表現することを目的としている。
SIOC Core Ontologyはオンライン上のコミュニティとその活動(例:掲示板、wiki、ウェブログ等)を記述するために使うことができる。
Schema.orgは、ウェブサイトのデザイナーがウェブページに構造化されたメタデータを記述することができる概念であり、Bing、Google、
Yahoo!等の主要なサーチエンジンで使用されている。Schema.orgは多様な分野のリソースを表現できるよう設計されている。
そのため、その他要素セットで区別される多くの要素が一つの項目に重複して入ることになり、豊富な図書館データを表現することができない。しかし、Eric Hellmaのブログ記事で示されているように、図書館やその他リソースに関するシンプルな情報の交換に使用することができる。
- xmlns:schema="http://schema.org/"
- 使用例:SEO
FacebookのOpen Graph「プロトコル」を使用することで、ソーシャルネットワークの参加者たちが興味を持つ、映画・音楽等のリソースを記述することが可能である。主な目的はウェブサイトにRDFaマークアップを埋め込み、ウェブページ上のオブジェクトに関するFacebookのデータをやりとりするために「いいね」ボタンと組み合わせて使えるようにすることである。
- xmlns:og="http://ogp.me/ns#"
- 使用例:SEO
メディアリソースのためのオントロジーでは、既存のメタデータ要素とマッピングしながら、メディアリソースに関する主要なメタデータのプロパティを定義し
ている。ローカルな文書館や博物館でしか利用できないリソースではなく、主にウェブ上で利用できるメディアリソースを対象としている。
5.2 RDF語彙として利用できるよう作業を行っているメタデータ要素セット
国際標準記録史料記述の一般原則では史料の検索手段として記述するべき要素を定義している。
EDMは、文化資源を対象にメタデータを記述し、そのデジタル形式へのアクセスを提供することを目的とした語彙である。EDMは、オブジェクトが複合的であり、複数のデータ提供者がオブジェクトに対して異なる見方をするというデータ集約の文脈に対応したものである。EDMは、他の要素セット特にOAI-ORE、Dublin Core、SKOS、CIDOC CRMを再利用し、拡張するほか、これらから影響を受けている。
EAC-CPFは、記録史料の文脈に関する典拠情報を表現することを目的としており、「著者、利用者またはレコードの主題となる個人・団体・家族の行為実体(エージェント)に関する識別や属性情報、エージェント間の関係性」も含まれる。[21]
同時に、記録史料の検索手段を表現する標準である符号化記録史料記述(EAD)への取組みも行われている。
EAC-CPFの主要な概念はエージェントとアイデンティティの区別である。例えば、同じエージェントでも異なるアイデンティティを持ちうる。また、一つのアイデンティティに複数のエージェントが対応することもある。
MARC (MAchine-Readable Cataloging)は図書館のメタデータの作成や交換において重要な役割を果たしている。MARC21全要素のRDF版が「MARC21形式のデータをRDF形式に可逆変換する基本的な方法」としてOpen Metadata Registry上で公開されている。これより前にMarcOnt initiativeが他のオントロジーに関連するMARC要素の小規模なサブセットを含む、OWLオントロジーを作成している。
- xmlns="http://marc21rdf.info/elements/"
- 使用例:Archipel
PREMISでは主要な保存メタデータ要素を定義し、広範囲のデジタル保存活動に適用できるデータ辞書をサポートしている。
EADはXMLを使って記録史料の検索手段を符号化した標準である。
LOCAH要素セットは一部のEADし
か扱っておらず、LOCAHの参加者がLinked
Dataとして記録史料のコレクションデータを公開する際に有用と見なした他の要素を取り入れている点に留意が必要である。また、記録史料や関連する名称
実体を記述するためのAaron Rubinsteinが管理する軽量なArchival語彙に関心を持つ読者もいるかもしれない。
ユースケースで利用されているメタデータ要素セットのうち、RDF語彙が利用できないメタデータ要素セット
美術作品記述カテゴリ(CDWA)は、美術作品、建築、その他物質文化、作品のグループやコレクション、関連画像についての情報を記述し、提供するための532のカテゴリとサブカテゴリを収録している。この要素のより簡易なサブセットであるCDWA
Liteも開発されている。
専門的な放送業界における番組情報に関連する情報のための標準的な語彙。
SPECTRUMは、オブジェクトの記述メタデータから貸出情報に至るまで、博物館のコレクションを管理するためのイギリスで作成された標準である。
MODSにはMARCフィールドのサブセットが含まれており、数字ではなく用語ベースのタグが用いられる。一部の要素では、MARC21書誌フォーマットの要素を再編成している。MODSはXMLを使って表現される。
「電子テキスの符号化と交換のためのガイドライン」はあらゆる種類の文学や言語学のテキストをオンライン上で検索または学習できるように表現するための標準である。
事例で言及されていないその他図書館分野に関連するメタデータ要素セット(非RDF語彙)
Visual Resources Association Core Categories (VRA Core)は、視覚的な文化作品や作品に関する画像を記述するレコードを作成するための主要な分類を特定している。
- VRA Core 3.0用のOWLオントロジーをW3C セマンティックウェブベストプラクティス・開発ワーキンググループのMark van Assemが開発している。
PBCoreは、デジタル放送とアナログ放送の両方を記述するためのメタデータ標準である。PBCore
XMLスキーマ定義
(XSD)では、PBCoreの構造と内容を定義している。要素セットと関連する値語彙がOpen Metadata Registryで利用できる。
献辞
図書館Linked DataインキュベータグループのメンバーであるMonica Duke、Ed Summers、Bernard Vatantが当文書を詳細に確認してくれた。
当報告書の公開時点では、LLD Data HubグループはKaren Coyle、Adrian Pohl、Ross Singer、Lars Svensson、そして既述の貢献者たちが維持管理している。
